I was struggling to define performance impact of Synchronous AG vs Asynchronous AGs in simple terms so DBAs and application teams could have an easy conversation about it. I searched internet and could not find any article that talks about it holistically. So, I decided to do some comprehensive testing and try to define impact in a way that is easy to understand and explain to application teams.
Setup
- Two VMs, AGTestSrvA and AGTestSrvB.
- Each VM has 8 CPUs and 16 GB RAM with Windows 2012 R2 standard edition clustered without shared storage.
- Each VM has three NICs in different subnets: First NIC for cluster heartbeat, Second NIC for AG data traffic, and Third NIC for user connections/traffic.
- VMs on different ESX hosts in same subnet.
- Backend storage is ExtremeIO.
- Default SQL 2014 Enterprise edition instance installed on each node with Always On enabled.
- Two database, MYDB_ASYNC and MYDB_SYNC.
- The two databases have 15 GB data files and 30 GB transaction log files just to make sure there is no need for them to expand during my testing.
- Data files for both databases are on same drive/same storage.
- Transaction log files for both databases are on same drive/same storage.
- Two Availability Groups, AG_MYDB_ASYNC and AG_MYDB_SYNC.
- AG_MYDB_ASYNC is setup with Asynchronous Commit between AGTestSrvA and AGTestSrvB. AGTestSrvA being primary and AGTestSrvB being secondary. This AG contains MYDB_ASYNC database.
- AG_MYDB_SYNC is setup with Synchronous Commit between AGTestSrvA and AGTestSrvB. AGTestSrvA being primary and AGTestSrvB being secondary. This AG contains MYDB_SYNC database.
Preparing databases for testing
I created three tables in each database.
- InsertSource: This table will be used as source of data to be inserted into another table called “Inserttest”. I will insert a million rows into InsertSource from which I will select rows in different batch sizes to insert into InsertTest table.
- InsertTest: This table will be one into which rows will be inserted from InsertSource.
- InsertsTracker: This table will be used to insert time taken by each batch to insert rows into InsertTest table.
Following is the script to create these three tables in each database.
CREATE TABLE [dbo].[InsertSource](
[InsertId] [INT] IDENTITY(1,1) NOT NULL,
[InsertText] [CHAR](1000) NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Inserttest](
[InsertId] [INT] IDENTITY(1,1) NOT NULL,
[InsertText] [CHAR](1000) NULL
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[InsertsTracker](
[NumberOfInserts] [int] NULL,
[TimeTaken] [datetime] NULL
) ON [PRIMARY]
GO
Following script will insert 1 million rows into InsertSource table.
DECLARE @text VARCHAR(1000);
SET @text = 'aaaaaaaaaaaaaaaaaaaaaaaaaabbbbbbbbbbbbbbbbbbbbbbcccccccccccccccccccccccCCCCCCCCDDDDDDDDDDDDDDDDDDDDE';
SET @text = @text + @text + @text + @text + @text + @text + @text + @text + @text + @text
DECLARE @cnt INT
SET @cnt = 1;
WHILE ( @cnt <= 1000000 )
BEGIN
INSERT INTO [InsertSource]( InsertText )
SELECT @text
SET @cnt = @cnt + 1
END
Testing Procedure
I create a SQL Agent job and scheduled it to run every minute. I create two steps in the job, the first one runs against MYDB_SYNC and second step runs against MYDB_ASYNC. Code for first step is below.
Use mydb_sync;
DBCC DROPCLEANBUFFERS --Clean memory
SELECT * FROM InsertSource -- Bring full source table into memory
DECLARE @start DATETIME --Variable to track start time of each batch
DECLARE @cnt INT
-- 1 million inserts of single row each
SET @start = GETDATE()
SET @cnt = 1
WHILE (@cnt<=1000000)
BEGIN
INSERT INTO [InsertTest] (inserttext)
SELECT TOP 1 InsertText FROM InsertSource
SET @cnt = @cnt + 1
END;
--Insert into tracker table the time it took to run the batch
INSERT INTO [dbo].[InsertsTracker]
SELECT 1000000,GETDATE() - @start
TRUNCATE TABLE InsertTest
BACKUP LOG mydb_sync TO DISK = 'nul:' --Clear tran log
WAITFOR DELAY '00:00:10' --Wait for 10 seconds before going to next batch
-- 100,000 inserts of 10 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=100000)
BEGIN
INSERT INTO InsertTest
SELECT TOP 10 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 100000,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
--10,000 inserts of 100 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=10000)
BEGIN
INSERT INTO InsertTest
SELECT TOP 100 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 10000,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
-- 1000 inserts of 1000 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=1000)
BEGIN
INSERT INTO InsertTest
SELECT TOP 1000 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 1000,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
-- 100 inserts of 10,000 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=100)
BEGIN
INSERT INTO InsertTest
SELECT TOP 10000 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 100,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
-- 10 inserts of 100,000 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=10)
BEGIN
INSERT INTO InsertTest
SELECT TOP 100000 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 10,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
-- 1 insert of 1 million rows
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=1)
BEGIN
INSERT INTO InsertTest
SELECT TOP 1000000 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 1,GETDATE() - @start
TRUNCATE TABLE InsertTest
BACKUP LOG mydb_sync TO DISK = 'nul:'
Code for second step that runs against MYDB_ASYNC is as follows.
Use mydb_async;
DBCC DROPCLEANBUFFERS --Clean memory
SELECT * FROM InsertSource -- Bring full source table into memory
DECLARE @start DATETIME --Variable to track start time of each batch
DECLARE @cnt INT
-- 1 million inserts of single row each
SET @start = GETDATE()
SET @cnt = 1
WHILE (@cnt<=1000000)
BEGIN
INSERT INTO [InsertTest] (inserttext)
SELECT TOP 1 InsertText FROM InsertSource
SET @cnt = @cnt + 1
END;
--Insert into tracker table the time it took to run the batch
INSERT INTO [dbo].[InsertsTracker]
SELECT 1000000,GETDATE() - @start
TRUNCATE TABLE InsertTest
BACKUP LOG mydb_async TO DISK = 'nul:' --Clear tran log
WAITFOR DELAY '00:00:10' --Wait for 10 seconds before going to next batch
-- 100,000 inserts of 10 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=100000)
BEGIN
INSERT INTO InsertTest
SELECT TOP 10 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 100000,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
--10,000 inserts of 100 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=10000)
BEGIN
INSERT INTO InsertTest
SELECT TOP 100 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 10000,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
-- 1000 inserts of 1000 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=1000)
BEGIN
INSERT INTO InsertTest
SELECT TOP 1000 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 1000,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
-- 100 inserts of 10,000 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=100)
BEGIN
INSERT INTO InsertTest
SELECT TOP 10000 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 100,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
-- 10 inserts of 100,000 rows each
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=10)
BEGIN
INSERT INTO InsertTest
SELECT TOP 100000 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 10,GETDATE() - @start
TRUNCATE TABLE InsertTest
WAITFOR DELAY '00:00:10'
-- 1 insert of 1 million rows
SET @cnt = 1
SET @start = GETDATE()
WHILE (@cnt<=1)
BEGIN
INSERT INTO InsertTest
SELECT TOP 1000000 InsertText FROM InsertSource WITH(NOLOCK)
SET @cnt = @cnt +1
END;
INSERT INTO [dbo].[InsertsTracker]
SELECT 1,GETDATE() - @start
TRUNCATE TABLE InsertTest
BACKUP LOG mydb_async TO DISK = 'nul:'
Notice that the code is essentially the same except for the USE and BACKUP LOG commands, where we need to specify database name.
I used following queries to get the stats from InsertsTracker table that will be used to populate excel worksheet.
USE Mydb_sync
GO
SELECT *,DateDiff(Millisecond, 0,TimeTaken) AS [Sync ms],ROW_NUMBER() OVER (PARTITION BY NumberOfInserts ORDER BY TimeTaken) AS RowNo,
CAST((PERCENT_RANK( ) OVER ( PARTITION BY NumberOfInserts ORDER BY TimeTaken ))*100 AS INT) AS Prc
INTO #tmp
FROM insertstracker
ORDER BY NumberOfInserts, TimeTaken DESC
--Get the minimum numbers
SELECT * FROM #tmp WHERE RowNo = 1 ORDER BY NumberOfInserts DESC
--Average numbers
SELECT NumberOfInserts,AVG([Sync ms]) as Average_ms FROM #tmp Group by NumberOfInserts ORDER BY NumberOfInserts DESC
--50th percentile
SELECT * FROM #tmp WHERE Prc BETWEEN 48 AND 52 ORDER BY NumberOfInserts DESC
--80th percentile
SELECT * FROM #tmp WHERE Prc BETWEEN 78 AND 82 ORDER BY NumberOfInserts DESC
DROP table #tmp
USE Mydb_async
GO
SELECT *,DateDiff(Millisecond, 0,TimeTaken) AS [Async ms],ROW_NUMBER() OVER (PARTITION BY NumberOfInserts ORDER BY TimeTaken) AS RowNo,
CAST((PERCENT_RANK( ) OVER ( PARTITION BY NumberOfInserts ORDER BY TimeTaken ))*100 AS INT) AS Prc
INTO #tmp
FROM insertstracker
ORDER BY NumberOfInserts, TimeTaken DESC
--Get the minimum numbers
SELECT * FROM #tmp WHERE RowNo = 1 ORDER BY NumberOfInserts DESC
--Average numbers
SELECT NumberOfInserts,AVG([Sync ms]) as Average_ms FROM #tmp Group by NumberOfInserts ORDER BY NumberOfInserts DESC
--50th percentile
SELECT * FROM #tmp WHERE Prc BETWEEN 48 AND 52 ORDER BY NumberOfInserts DESC
--80th percentile
SELECT * FROM #tmp WHERE Prc BETWEEN 78 AND 82 ORDER BY NumberOfInserts DESC
DROP table #tmp
I monitored disk IO, Memory, CPU, and Network utilization throughout the test and none of them were taxed at any time. I did this to make sure that none of the resources are bottleneck and affecting results. The testing result should be purely a factor of Synchronous vs Asynchronous modes of Availability groups and size of inserts.
I ran the job for a couple of days and got more than 50 data points.
Test Results
After having this job run for a couple of days, following were the results.
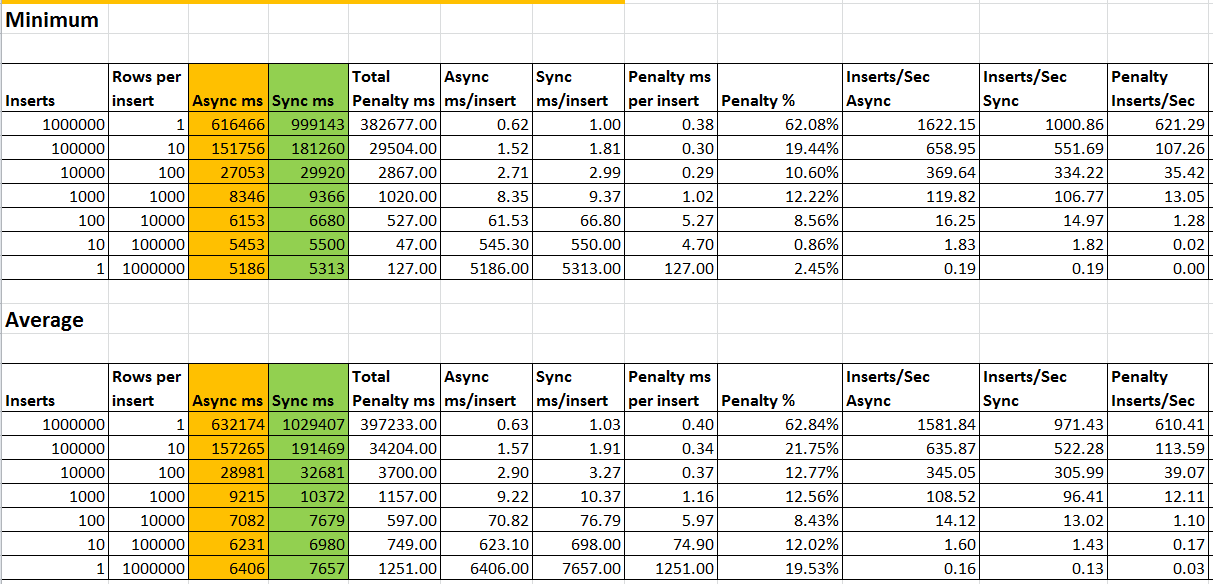
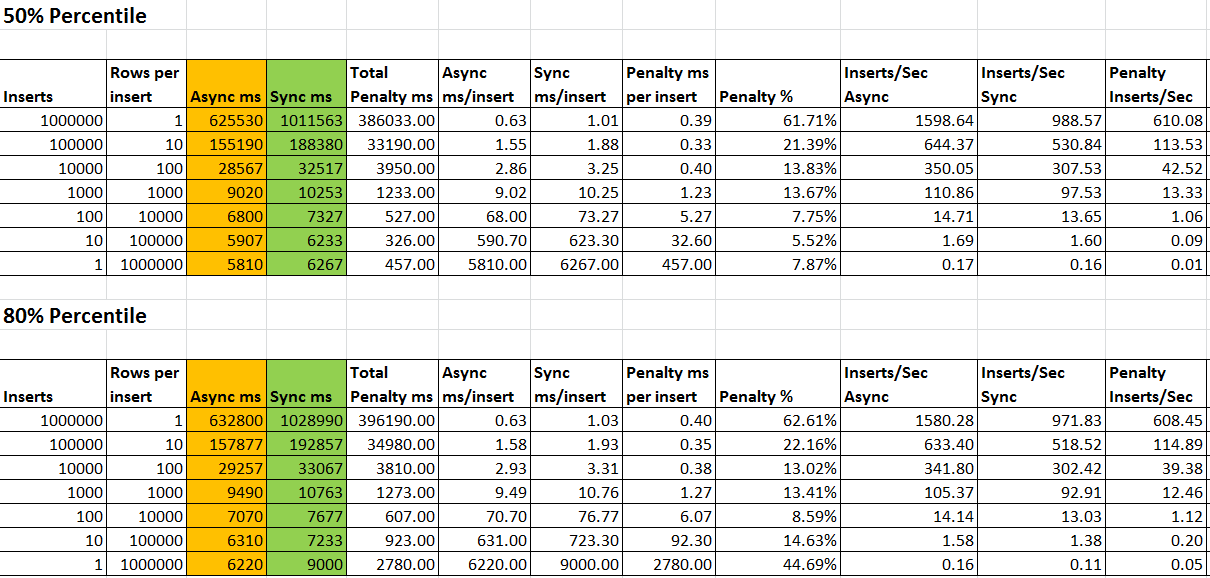
Let us talk about the columns and what they mean.
- (Inserts): Number of inserts statements run in the batch. One insert statement may have 1 or more than 1 rows being inserted. Each insert is an implicit transaction.
- (Rows per insert): Number of rows inserted into InsertsTest table in each insert statement. First line is 1 million inserts of 1 row each; second line is 100,000 inserts of 10 rows each; third line is 10,000 inserts of 100 rows each, and so on.
- (Async ms): shows the total time in milliseconds taken for the batch to run in MYDB_ASYNC database, which has Asynchronous Commit.
- (Sync ms): shows the total time in milliseconds taken for the batch to run in MYDB_SYNC database, which has Synchronous Commit.
- (Total Penalty ms) = (Sync ms) – (Async ms). It is how much longer the batch took in Synchronous mode compared to Asynchronous mode.
- (Async ms/Insert) = (Async ms)/(Inserts). It is the number of milliseconds it took per insert(not per row) in Asynchronous mode.
- (Sync ms/Insert) = (Sync ms)/(Inserts). It is the number of milliseconds it took per insert(not per row) in Synchronous mode.
- (Penalty ms per Insert) = (Sync ms/Insert) - (Async ms/Insert). It is the delay that Synchronous mode added to each insert over Asynchronous mode.
- (Penalty %) = ((Penalty ms per Insert)x100)/(Async ms/Insert). It is the percentage penalty of Synchronous over Asynchronous per insert. It is also true for the whole batch.
- (Inserts/Sec Async) = ((Inserts)x1000)/(Async ms). Number of inserts per second in Asynchronous mode.
- (Inserts/Sec Sync) = ((Inserts)x1000)/(Sync ms). Number of inserts per second in Synchronous mode.
- (Penalty Inserts/Sec) = (Inserts/Sec Async) - (Inserts/Sec Sync). It is the impact that Synchronous mode has in terms of number of inserts per second.
With one million single row inserts, the Synchronous mode has more than 60% degradation in batch performance compare to Asynchronous mode. As the nature of batch changes such that number of inserts reduces and number of rows in each insert increases, the impact of Synchronous mode on batch performance reduces and it gets closer to Asynchronous performance.
This testing was done with ExtremeIO storage on both VMs. If the backend storage is of a slower kind, the percentage impact of Sync vs Async may be different. The stats from a VNX storage setup are below. LUNs had a mix of SSD and SATA drives. Notice that even though the penalty per insert is higher than ExtremeIO, the percentage of penalty is lower than ExtremeIO. The reason for this is that the time taken for each insert is also higher, which lowers the percentage impact. What is also strange is that Sync perfosm better than Async on larger transactions. I have not found explanation of this yet.
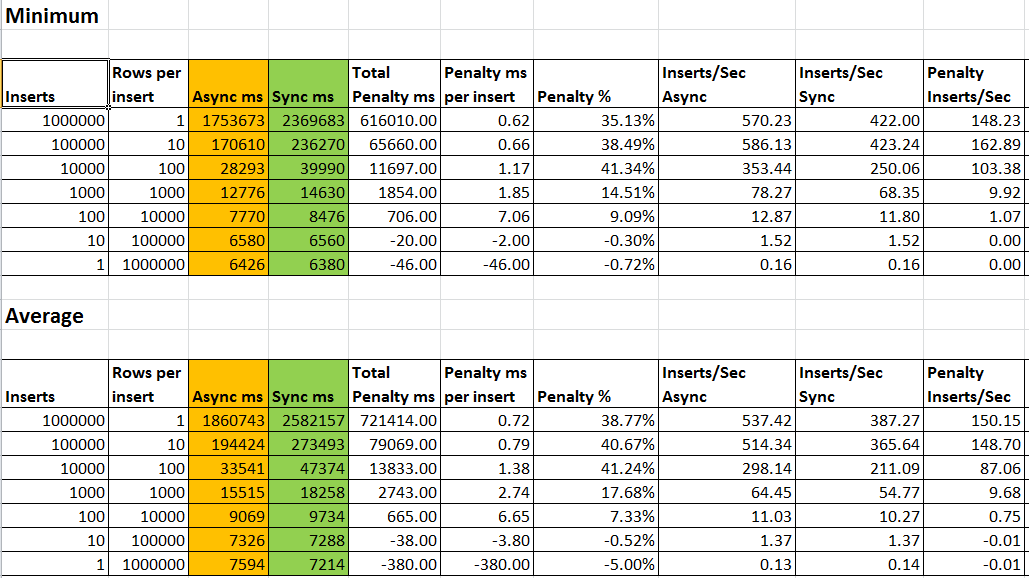

Conclusion
Performance impact of Synchronous mode in Availability Groups cannot be pinned to fixed number or even a narrow range. It varies based on the type of transactions, size of batches the application runs, and underlying storage. If there are other resource bottlenecks, they can have their effect, mostly negative, on the performance.
No comments:
Post a Comment